 |

Красинский В.И.
Центральный сибирский ботанический сад СО РАН, Новосибирск
После первообразной работы Л.Заде [1] по нечетким множествам (НМ) С.Ватанабэ предложил и обосновал [2] обобщение классической функции истинности предикатов на непрерывный интервал [0,1]. Этот подход оказался плодотворным для моделирования тех задач и ситуаций, в которых отсутствуют приборные показания, также для формализации знаний. Преобразование нечетких значений признаков объектов в значения функции принадлежности (ФП) объектов к НМ соответствует измерению этих признаков в единой абстрактной интервальной шкале, что открывает возможности для нестатистического многомерного анализа и классификации. Семантика и алгоритмы этих преобразований составляют предмет прикладных исследований.
Значительной трудностью в задачах диагностики в биологии, в частности, ботанике, является многозначность классов-таксонов по всем признакам. Иначе говоря, значениями числовых и номинальных признаков классов являются списки переменной длины. В такой ситуации невозможно четкое разбиение универсума на подмножества по значениям признаков - нет полной группы несовместных событий по значениям признаков. Многозначность образов-классов соответствует их пересечениям. Поэтому чаще всего неприменимы методы теории вероятностей и математической статистики для моделирования процессов распознавания реальных биологических объектов.
Целью работы являлось создание алгоритма и соответствующей программы @RECOFAM (Recognizer of Families) для диагностики двудольных растений Сибири на уровне семейств. Исходные данные предоставлены д.б.н. И.М.Красноборовым. Классы-семейства растений (всего 102) представлены значениями 11 морфологических признаков: четырех числовых - чисел пестиков, столбиков, тычинок, листочков околоцветника, и семи номинальных - типов околоцветника, соцветия, плода, размножения, завязи, гинецея, листьев.
По всем признакам классы многозначны (нечеткие в признаковом пространстве). Например, по признаку ``тип соцветия'' семейство растений Fabaceae характеризуется списком трех значений: головка, кисть, цветки одиночные. По этому же признаку ``тип соцветия'' семейство Primulaceae имеет список из пяти значений: зонтик, кисть, метелка, цветки одиночные, цветки пазушные. Видно, что эти таксоны частично пересекаются (похожи) по признаку типа соцветия. Пример многозначности по числовому признаку: у растений семейства Saxifragaceae число лепестков бывает 1, 4, 5. Отсюда видна недостаточность интервального способа учета неопределенности для реальных биологических объектов - представители последнего таксона не могут иметь число лепестков 2, 3.
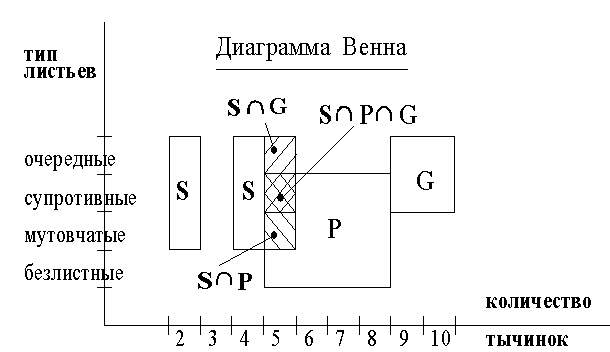
Дополнительные примеры многозначности трех классов-семейств по двум разнотипным признакам приведены в табл. 1. Ниже, на рис. 1, показана соответствующая диаграмма Венна, иллюстрирующая пересечения и разрывы классов-семейств в признаковом пространстве.
Пересечение классов можно трактовать как зашумленность данных, или информационную избыточность. Для оценки средней степени информационной избыточности описания пересекающихся классов-таксонов предлагается коэффициент эксцесса:
Коэффициент ![]() равен единице в стандартном случае не пересекающихся
по значениям признаков классов объектов, то есть в случае полной группы
несовместных событий. Он позволяет приближенно оценить среднюю степень
неопределенности описания классов как по каждому признаку в отдельности, так
и в целом, по всем признакам. Будучи вычисленным по всей исходной двоичной
таблице экспериментальных данных (ТЭД 102
равен единице в стандартном случае не пересекающихся
по значениям признаков классов объектов, то есть в случае полной группы
несовместных событий. Он позволяет приближенно оценить среднюю степень
неопределенности описания классов как по каждому признаку в отдельности, так
и в целом, по всем признакам. Будучи вычисленным по всей исходной двоичной
таблице экспериментальных данных (ТЭД 102![]() 94), этот
коэффициент получил значение
94), этот
коэффициент получил значение ![]() , которое в точности равно пропорции
золотого сечения, одного из фундаментальных законов природы и искусства.
, которое в точности равно пропорции
золотого сечения, одного из фундаментальных законов природы и искусства.
Соответствие строения и количества разных органов растений числам Фибоначчи
известно ботаникам еще со средних веков. Поскольку исходная ТЭД является
обобщающей по большинству растений Сибири, факт ![]() можно считать не
случайным, а свидетельствующим об удачном выборе ботаниками системы
признаков для описания семейств растений. Анализ этого факта выходит за
рамки проведенного исследования, требуется глубокая биологическая
интерпретация. Возможно, в ``золотой'' степени информационной избыточности ТЭД
отражается универсальное антиэнтропийное свойство живых систем для
сохранения своей устойчивости во внешнем мире.
можно считать не
случайным, а свидетельствующим об удачном выборе ботаниками системы
признаков для описания семейств растений. Анализ этого факта выходит за
рамки проведенного исследования, требуется глубокая биологическая
интерпретация. Возможно, в ``золотой'' степени информационной избыточности ТЭД
отражается универсальное антиэнтропийное свойство живых систем для
сохранения своей устойчивости во внешнем мире.
Применение классических статистических методов, основанных на аксиоматической теории вероятностей, (программные пакеты СИГАМД, STATISTICA) для диагностики растений не привело к успеху именно из-за пересечения классов-таксонов. Поэтому использование теории нечетких множеств и теории возможностей для моделирования многозначности в описаниях классов было вполне обоснованным. Семантика всех НМ-признаков определена как ``ненадежность диагностики'', а именно, чем более многозначен таксон-семейство, тем хуже распознаются его представители по данному признаку. Такая семантика нечеткости таксонов подтверждена ботаниками и поэтому служит цели создания оптимизирующего диалогового алгоритма распознавания (диагностики) растений. Вычисление степени нечеткости многозначных таксонов по каждому признаку снижает размерность признакового пространства, и является преобразованием в сильную интервальную шкалу списковых признаков классов-таксонов, то есть классы становятся ранжированными по каждому признаку (количественному и качественному), причем по единой мере, что создает условия для многомерного анализа.
Цель алгоритма последовательной интерактивной диагностики состоит в минимизации количества вопросов о значениях признаков диагностируемой особи, на основе интегрального критерия, получаемого суперпозицией всех НМ. Этот критерий вычисляется на всех оставшихся кандидатах-таксонах. Применяются три метода суперпозиции НМ: по минимальной нечеткости, по средней нечеткости, по минимуму коэффициента нечеткости Кофмана. Возможен ответ пользователя ``не знаю'' на вопрос о значении любого признака, при этом не возникает тупиковой ситуации, а лишь удлиняется диалог. Реализованный алгоритм соответствует распознающему алгоритму в смысле работы [3], при этом вычисление ФП объектов-классов к НМ по значениям признаков позволило получить числовой интегральный критерий качества диагноза особи, избегая неопределенностей, отмеченных в [3].
Для вычисления ФП многозначных объектов к НМ (степени нечеткости) по
числовым признакам разработан новый способ [4], основанный на понятии
фокальных элементов (ФЭ, или вложенных подмножествах универсума). Вместо
распределения вероятностей значений признака вычисляются распределения мер
возможности и необходимости этих значений по двум последовательностям ФЭ
исходного множества объектов, в соответствии с теорией Демпстера-Шефера [5],
в которой требование полноты группы несовместных событий заменяется
распределением единичной ``массы уверенности'' на все возможные события
(значения признака). А именно, исходное множество X нечетких объектов
разбивается на непустые, попарно различные четкие подмножества
| (1) |
| (2) |
В совокупности выражений (1) и (2) состоит принцип получения приращения
необходимости события i (аналогично вычислению эмпирической функции
распределения вероятностей событий). Вычисление ФП объектов к НМ по
распределению меры необходимости универсума обосновано в работе [7]:
| (3) |
Поскольку признак числовой, то можно построить две последовательности ФЭ в
соответствии с группами противоположных событий ``быть меньше или равно
![]() '' и ``быть больше
'' и ``быть больше ![]() '', где
'', где ![]() -
значение признака в
-
значение признака в ![]() -интервале группировки. Соответственно вычисляются по
(3) ФП к двум НМ - слева
-интервале группировки. Соответственно вычисляются по
(3) ФП к двум НМ - слева ![]() и справа
и справа ![]() . Это позволяет максимально учесть
многозначность числовых объектов-классов. Свертка НМ
. Это позволяет максимально учесть
многозначность числовых объектов-классов. Свертка НМ ![]() ,
, ![]() в единое НМ
в единое НМ ![]() производится по принципу расширения Заде:
производится по принципу расширения Заде:
| (4) |
Отметим, что предложенный способ формализации нечеткости полностью применим к объектам, описанным ранговыми признаками, так как по ним точно так же можно построить две фокальные последовательнности объектов.
Вычисление ФП таксонов к НМ для номинальных признаков производится на основе теории возможностей с учетом весовых коэффициентов, или ``масс уверенности'' в значениях признаков у многозначных таксонов [8], [9].
Общий алгоритм диагностики неизвестного растения [9], работающий с нечеткими
множествами ``надежность диагноза ![]() '', состоит из трех
основных циклически выполняемых блоков:
'', состоит из трех
основных циклически выполняемых блоков:
1. Для каждого из оставшихся семейств-кандидатов на диагноз (сначала это все 102 семейства) вычисляются значения функций принадлежности ко всем 11 НМ-признакам.
2. Выбор очередного вопроса по результату суперпозиции (свертки) всех НМ - ранжирование признаков по итоговому критерию априорной надежности диагноза оставшихся объектов. Реализованы три принципа свертки НМ. ``По умолчанию'' установлена осторожная стратегия, но пользователь может изменять выбор.
2.1. Осторожная стратегия, или усредненный выбор, состоит в том, что вычисляется среднее значение ФП для каждого из 11 признаков на всех оставшихся объектах. Признаки ранжируются по убыванию этой ``средней надежности диагноза''. Пользователь, однако, может выбрать любой признак из списка, не обязательно следуя рекомендации программы.
2.2. Рискованная стратегия, или экстремальный выбор, состоит в том, что признаки ранжируются по убыванию максимальных значений своих ФП. Выбрать можно также любой признак. Эта стратегия в небольшом числе случаев дает быструю диагностику (за 1 - 2 ответа на вопросы программы).
2.3. Одним из показателей для оценки степени нечеткости НМ является
коэффициент Кофмана ![]() - чем он меньше, тем лучше
соответствующий признак m подходит для диагностики:
- чем он меньше, тем лучше
соответствующий признак m подходит для диагностики:
В программе применяется равноценное операции ![]() ядро
ядро
![]() , на
основе которого можно получить расстояние Хемминга-Заде между НМ и его
отрицанием:
, на
основе которого можно получить расстояние Хемминга-Заде между НМ и его
отрицанием:
Это соответствует минимуму нечеткости по Кофману, то есть объекты-классы менее всего ``размазаны'' по градациям значений этого признака, по сравнению со всеми другими.
3. По ответу на вопрос о значении признака, выбранного в п.2, и в соответствии с таблицей исходных данных о 102 таксонах, производится ограничение множества семейств-кандидатов на диагноз, затем - переход к п.1, и так до одного кандидата, либо до появления противоречий в ответах пользователя.
Разработанный алгоритм пошаговой диагностики растениий является примером советующей экспертной системы - анализу по совокупности разнотипных признаков неопределенных ситуаций в целях поиска наилучшего прецедента, среди описанных экспертом. Растения однозначно диагностируются в среднем за 2-4 ответа на вопросы программы о значениях признаков, вместо полного вектора из 11 значений. Программа не имеет тупиковых ситуаций, тестирование ведущими ботаниками подтвердило ее надежность. Ниже, в табл. 2, 3, приводятся примеры диагностики растений по программе @RECOFAM.
| Вопрос | Ответ | Осталось кандидатов (из 102) |
|---|---|---|
| 1. листья | стебель безлистный | 12 |
| 2. соцветие | зонтик | 1 - Primulaceae |
| Вопрос | Ответ | Осталось кандидатов (из 102) |
|---|---|---|
| 1. соцветие | метелка | 26 |
| 2. плод | не знаю | 26 |
| 3. андроцей | 2 тычинки | 5 |
| 4. столбики | 3 | 1 - Rosaceae |
Видно, что в примере по табл. 3 ответ ``не знаю'' на вопрос о типе плода не сорвал диагностику представителя этого сложного семейства. Подобное ``разумное'' поведение программы является следствием избыточности исходной информации (большого числа признаков) и описанных выше оптимизационных свойств алгоритма диагностики.
Эффективность алгоритма демонстрируется в табл. 4 путем сравнения количества вопросов до однозначной диагностики одних и тех же растений (представителей трех трудных таксонов) по советам программы и вопреки советам программы, также при выборе очередного признака-вопроса по датчику случайных чисел.
| Семейство | По алгоритму | Вопрос по датчику случайных чисел | Вопреки алгоритму |
|---|---|---|---|
| Capryophyllaceae | 2 | 7 | 7 |
| Ranunculaceae | 3 | 5 | 4 |
| Rosaceae | 2 | 5 | 9 |
Видно явное превосходство действий пользователя в соответствии с рекомендациями программы, по сравнению с другими способами выбора признаков для диагностики одних и тех же растений.
Программа @RECOFAM внедрена в учебный процесс как учебное пособие (тренажер по курсу флористики) для студентов и аспирантов на кафедрах ботаники двух государственных педагогических университетов - Новосибирского и Омского.
Предложенный метод распознавания многомерных неопределенных объектов (ситуаций) по отношению к пересекающимся классам является весьма универсальным, поскольку очень многие реальные технические и научные объекты или понятия могут быть представлены совокупностью списковых значений количественных и качественных признаков. Ситуации ``не знаю'' по значению любого признака соответствуют в технологических задачах отказам каналов измерительной информации, поэтому применение разработанного алгоритма может значительно повысить надежность всей системы управления (идентификации). Многозначные классы объектов в различных задачах могут отражать наличие помех на фоне сигнала, разнообразие мнений экспертов о сложных ситуациях, группированные данные социологических опросов. То есть применение теории нечетких множеств открывает перспективы для алгоритмического решения задач обработки данных в сложных реальных условиях.
ЛИТЕРАТУРА
 Ваши комментарии
Ваши комментарии
|
![[SBRAS]](/gif/s_sigma.gif)
[Головная страница] [Конференции] [СО РАН] |
© 2001, Сибирское отделение Российской академии наук, Новосибирск
© 2001, Объединенный институт информатики СО РАН, Новосибирск
© 2001, Институт вычислительных технологий СО РАН, Новосибирск
© 2001, Институт систем информатики СО РАН, Новосибирск
© 2001, Институт математики СО РАН, Новосибирск
© 2001, Институт цитологии и генетики СО РАН, Новосибирск
© 2001, Институт вычислительной математики и математической геофизики СО РАН, Новосибирск
© 2001, Новосибирский государственный университет
Дата последней модификации Monday, 03-Sep-2001 12:56:06 NOVST