Нейросетевая классификация объектов с
окрестностями.
Сенашова М.Ю. Институт вычислительного моделирования СО РАН, Красноярск
Аннотация:
Рассматривается задача разделения на классы объектов в -мерном
признаковом пространстве. Решающие правила строятся при помощи нейронных
сетей. На классы разделяются точки -мерного пространства с
окрестностями.
The problem of division into the classes the objects in -dimensional
characteristic space. The decision rule are obtained using the neural
network. The points of -dimensional space are divided into the classes with
some neighborhoods.
Пусть задан некоторый набор объектов
. Каждый объект
имеет признак
. Целевой признак
указывает, к какому классу относится объект . Объекты в
-мерном пространстве образуют облако точек. Нам требуется на основе
обучающей выборки
построить решающее правило ,
разделяющее точки -мерного пространства на классы с минимальными
ошибками. Решающее правило должно принимать положительные значения в
точках одного класса и отрицательные значения в точках другого класса.
Разделяющая поверхность будет нулями этой функции.
Решающее правило может быть линейной или нелинейной функцией. Линейные
решающие правила требуют меньших вычислительных затрат, но они не всегда
хорошо разделяют классы. Часто приходится строить наборы линейных решающих
правил или кусочно-линейные правила. Нелинейные решающие правила обычно
хорошо разделяют классы, но при этом возникает проблема выбора подходящей
функции, поскольку таких функций можно задать бесконечно много. Чтобы
выбрать вид нелинейного решающего правила, нужно задать какие-либо
ограничения. Это могут быть либо требования к свойствам функции, либо
функция должна разделять на классы точки с некоторыми окрестностями.
Если мы налагаем ограничения на свойства функции, то можно требовать, чтобы
эта функция была достаточно гладкой, вторые производные были не очень велики
и т.д. Один из способов построения нелинейных решающих правил -- это решение
задачи распознавания образов при помощи нейронных сетей. В этом случае
ограничения на функцию задаются как ограничение на количество нейронов и/или
слоев нейронной сети. В данной работе мы будем рассматривать построение
решающих правил при
помощи нейронных сетей. Решающие правила строятся нейронными сетями в
процессе обучения сети решать задачу распознавания образов на заданной
обучающей выборке
. Нейронные сети обучаются методом
обратного распространения ошибки.
Очень часто при решении практических задач встречаются ситуации, когда
классы сильно отличаются по мощности. В случае, если класс малой мощности не
играет большой роли при решении задачи классификации, его можно объединять с
другими классами. Однако классы малой мощности зачастую играют важную роль и
объединение их с другими классами искажает смысл. В этом случае следует
каким-либо образом увеличить мощность таких классов. Это можно делать
различными способами. Можно убирать значение одной или нескольких компонент
вектора входных данных. При этом точки многомерного пространства
превращаются в линейные многообразия. Можно случайным образом сдвигать
координаты внутри некоторого радиуса . Один из способов
увеличения мощности класса -- разделять на классы не точки многомерного
пространства, а точки с окрестностями.
Разделение на классы точек с окрестностями позволяет решать задачу
классификации с некоторым запасом точности. В этом случае ограничения
налагаются также на вид и размер окрестностей. Окрестности могут быть либо
многомерными сферами, либо многомерными параллелепипедами, либо
эллипсоидами. Желательно, чтобы окрестности были максимального размера.
Однако, разделяющая функция тоже должна быть достаточно гладкая и иметь не
очень большие вторые производные. При использовании нейронных сетей
выполнения этих условий добиваются минимизацией количества нейронов в сети.
Поскольку точки с окрестностями должны пропускаться по нейронной сети, то
нелинейные искажения формы существенно осложнят дело -- образ эллипсоида
может даже потерять выпуклость и т.п. Поэтому предлагается компромиссный
``инфинитизимальный'' подход: ``центры окрестностей'' преобразуются
нелинейными преобразователями, а преобразование окрестностей производится
операторами линейного приближения (дифференциалами) нелинейных отображений.
Желательно, чтобы класс рассматриваемых окрестностей был инвариантен
относительно линейных преобразований. Этому условию отвечают, например,
класс всех параллелепипедов или класс эллипсоидов.
Будем рассматривать окрестности вида
, где - вектор
входных сигналов,
, а
- это либо вектор полуосей, если мы выбираем окрестности в виде
эллипсоидов, либо вектор полудлин интервалов. При этом будем использовать не
саму функцию нейрона, а ее линейное приближение. То есть на каждом слое
нейронной сети будет строиться касательная плоскость к решающему правилу.
Рассмотрим, как работает нейронная сеть с окрестностями такого вида и
линейными приближениями функций нейронов. Предположим, что нейронная сеть
должна разделить объекты на два класса. Пусть нейронная сеть имеет один
выход. При этом выходные сигналы для объектов первого класса принимают
положительные значения, а выходные сигналы для объектов второго класса
принимают отрицательные значения.
При обучении нейронной сети значения векторов сначала пропускаются по
сети в прямом направлении, и вычисляется значение функции оценки. Затем
полученное значение функции оценки пропускается по сети в обратном
направлении. При этом происходит собственно обучение сети, то есть изменение
весов синапсов.
В нашем случае, для обучения нейронной сети необходимо знать, как проходят
по сети в прямом направлении сигналы
и вид функции
оценки, позволяющей строить нужное нам решающее правило.
Мы будем использовать сети слоистой структуры. Выясним, как проходят сигналы
с окрестностями через некоторый стандартный нейрон слоя, поскольку нейрон
является типичным участком сети. Стандартный нейрон состоит из сумматора и
нелинейного преобразователя. Пусть на входы сумматоров слоя подаются сигналы
вида
. При прохождении сигналов через сумматор получаем:
При прохождении сигнала
через нелинейный
преобразователь пользуемся линейным приближением:
. Таким образом, вид сигналов при прохождении через
слой сети сохраняется. На выходе сети мы также имеем сигнал вида
, где - выходной сигнал, соответствующий вектору
входных сигналов , а - полуось эллипса выходного сигнала (или
полудлина интервала, в зависимости от вида выбранной окрестности). То есть
при прохождении окрестностей через нейронную сеть вычисляется значение
функции в центре окрестности и длина полуоси или полуинтервала.
Нам требуется, чтобы выполнялось следующее условие. Если выходной сигнал
принадлежит какому-то классу, то сигнал
должен
принадлежать этому же классу. Исходя из этих соображений, будем строить
функцию оценки для обучения сети методом обратного распространения
ошибки. Предположим, что выходные сигналы объектов, принадлежащих первому
классу положительны. Тогда положительным должно быть и значение
. Если для вектора входных сигналов объекта,
принадлежащего первому классу, это значение действительно положительное, то
при данных весах синапсов этот объект относится сетью к своему классу вместе
с окрестностью и обучение не требуется. В случае, если значение
отрицательное, то сеть нужно обучать и функция оценки имеет
вид
.
Для объектов второго класса рассуждаем аналогично. Выходной сигнал объекта,
принадлежащего второму классу, должен быть отрицательным. Тогда
отрицательным должно быть и значение
. В случае, если
выходной сигнал отрицательный, то для данного объекта обучать сеть не
требуется. Если же значение
положительное, то
функция оценки имеет вид
.
Таким образом, для всего набора объектов функция оценки имеет следующий вид:
Поскольку проходит сеть насквозь, то изменяя
можно обучить сеть разделять на классы точки с максимальными окрестностями.
Изначально задается вид эллипсоида (то есть вектор полуосей и
произвольная величина . Если при данной величине сеть обучается разделять на классы точки с окрестностями, то величину
можно увеличить в раз. Если при данном
сеть не обучается, то величину уменьшаем, выбирая, например
. Изменяя таким образом величину обучаем сеть относить к нужному кассу точки с максимальными окрестностями.
В качестве вида окрестности можно выбирать эллипсоид рассеяния точек
выборки. Параметр позволит получить максимальные окрестности
такого вида при которых сеть правильно разделяет точки на классы. Полуоси
эллипсоида рассеяния могут быть вычислены для каждого класса отдельно. То
есть вид окрестностей будет различным для точек из разных классов.

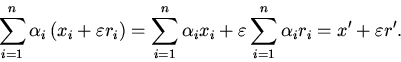
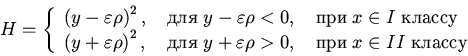

![[SBRAS]](/gif/s_sigma.gif)